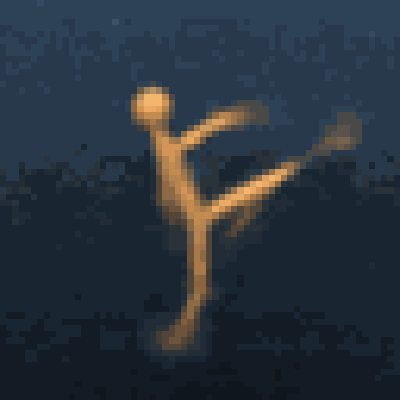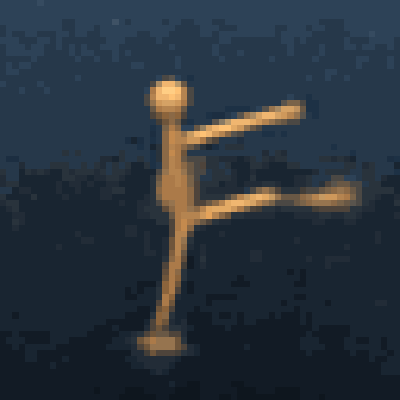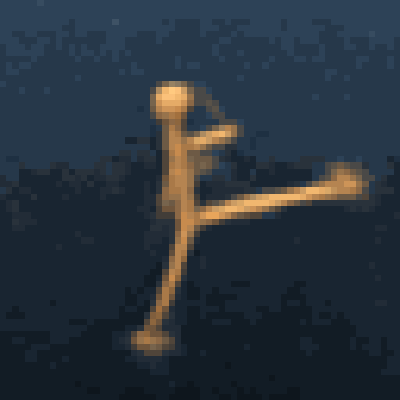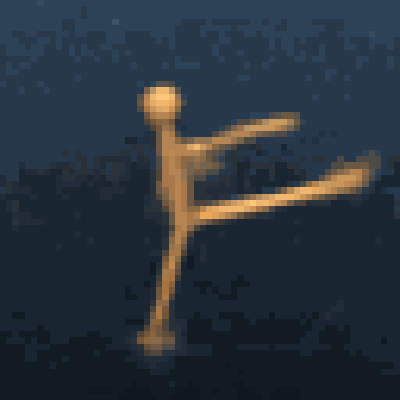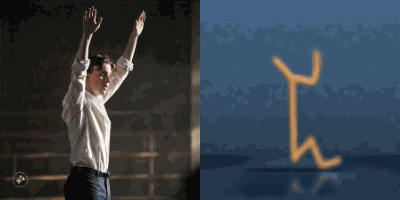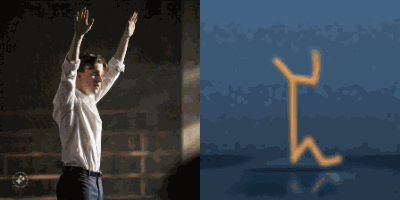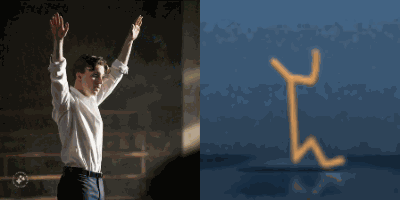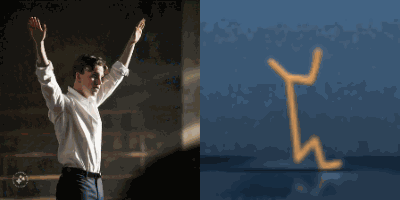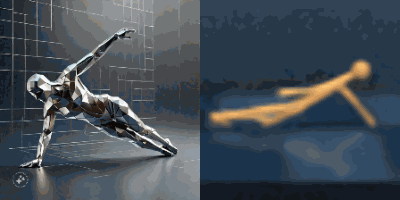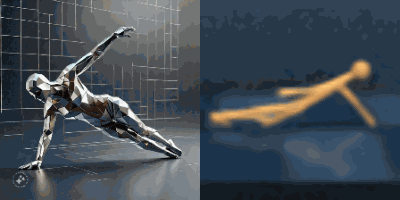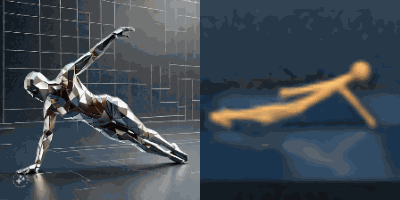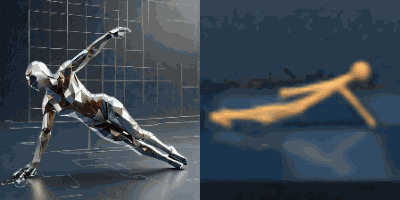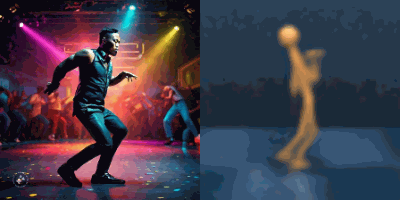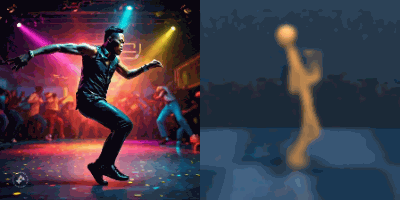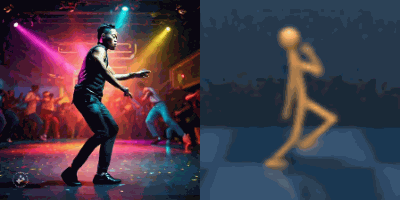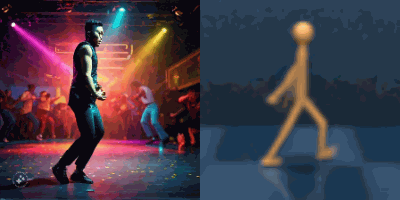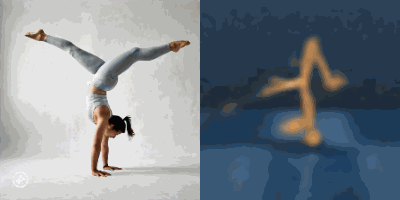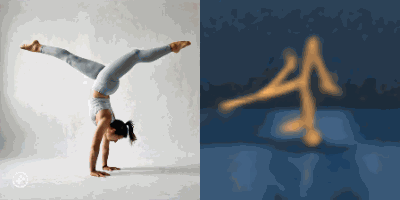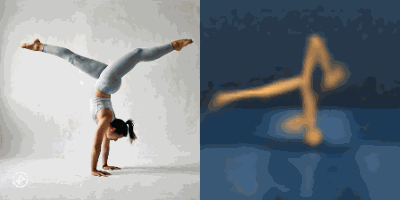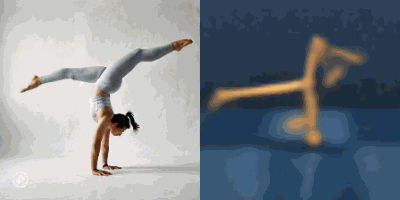Multimodal foundation world models
for generalist embodied agents
Anonymous authors

Multimodal foundation world models allow grounding language and video prompts into embodied domains, by turning them into sequences of latent world model states.
Latent state sequences can be decoded using the decoder of the model, allowing visualization of the expected behavior, before training the agent to execute it.
Latent state sequences can be decoded using the decoder of the model, allowing visualization of the expected behavior, before training the agent to execute it.